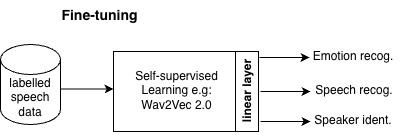
A Wide List of Phoneme-Labeled (Human & Force-Aligned) Speech Datasets Across High- and Low-Resource Languages
Introduction
Phoneme recognition is a fundamental problem in speech processing, particularly in low-resource speech recognition, because collecting human-labeled, time-stamped phoneme annotations is an expensive and labor-intensive job — and it is especially challenging for low-resource languages. Below is a compiled list of available resources for phoneme-labeled datasets, spanning hand-labeled corpora, force-aligned corpora, and multilingual and endangered-language collections.
1. Hand-Labeled Time-Aligned Phoneme Datasets — English
| Dataset | Language | Size | Annotation Type | Speech Type | Notes |
|---|---|---|---|---|---|
| TIMIT MIT / SRI / TI, 1993 |
English | 5.4 hrs, 630 speakers | Expert hand-labeled, time-aligned | Read speech | 60-phoneme ARPAbet inventory, foldable to 48 or 39. Gold standard for phoneme recognition. Available via LDC (LDC93S1). |
| Buckeye Corpus Pitt et al., 2007 |
English | 40 hrs, 40 speakers | Hand-corrected, time-aligned | Spontaneous / conversational | Phoneme- and word-level annotations; hand-verified alignments. Ohio American English speakers. Freely available. |
| TORGO Rudzicz et al., 2010 |
English | 23 hrs, 15 speakers | Expert labeled, time-aligned | Read / elicited (dysarthric + control) | Dysarthric speech from CP/ALS speakers + controls. Phoneme + articulatory (EMA) annotations. Clinically assessed. Publicly available. |
| MOCHA-TIMIT Univ. of Edinburgh, 1999 |
English | 0.5 hrs, 2 speakers | Expert labeled, time-aligned | Read speech | 460 TIMIT sentences with acoustic + EMA articulatory measurements. Phoneme boundaries hand-annotated. Free download. |
| OGI Multi-Language Telephone Speech OGI, 1994 |
English (+9 others) | 3 hrs | Expert labeled | Telephone / spontaneous | Human-labeled phoneme segments for 10 languages including English; used in LID and phoneme recognition research. LDC94S17. |
2. Human and Force-Aligned Time-Stamped Phoneme Datasets — Japanese
| Dataset | Language | Size | Annotation Type | Speech Type | Notes |
|---|---|---|---|---|---|
| CSJ (Corpus of Spontaneous Japanese) Maekawa, 2003 |
Japanese | 660 hrs, 1,400+ speakers | Expert (core subset), auto (rest) | Spontaneous (academic/public speech) | Core subset (45 hrs, 500K words) has manual phonetic labels + intonation annotation by experts. Full corpus has orthographic-only. NII Japan. |
| JSUT Sonobe et al., 2017 |
Japanese | 10 hrs, 1 speaker | Manual TTS labels | Read speech (single female) | 5,000 sentences with manually annotated phoneme + prosody labels for TTS. Freely available on GitHub. |
3. Phoneme-Labeled Dataset — Arabic
| Dataset | Language | Size | Annotation Type | Speech Type | Notes |
|---|---|---|---|---|---|
| Arabic Speech Corpus (MSA) Halabi, 2016 |
Arabic | 3.7 hrs, 1 speaker | Expert phoneme-level, time-aligned | Read speech (MSA) | Phonetic + orthographic transcriptions with word stress marks. Built for Arabic TTS/ASR research. Publicly available. |
4. Phoneme-Labeled Dataset — Chinese
| Dataset | Language | Size | Annotation Type | Speech Type | Notes |
|---|---|---|---|---|---|
| AISHELL-3 AISHELL, 2020 |
Mandarin | 85 hrs, 218 speakers | Professional annotation | Read speech (TTS) | Word- and tone-level transcriptions professionally annotated. Pinyin/phoneme-level labels included. Tone/prosody accuracy >98%. Free for research. |
5. Forced-Alignment Time-Aligned Phoneme Datasets — English
| Dataset | Language | Size | Annotation Type | Speech Type | Notes |
|---|---|---|---|---|---|
| LibriSpeech | English | 960 hrs, 2,484 speakers | Force-aligned labeled | Read audiobook speech | Phoneme labels obtained through forced alignment. Source: openslr.org/12 |
| Switchboard Godfrey et al., 1992 |
English | 260 hrs, 543 speakers | Partial expert, forced-align (rest) | Telephone / conversational | 5,000 utterances have human phoneme transcriptions (Greenberg et al., 1996); rest are G2P/forced-aligned. LDC2002T43. |
6. Multilingual Force- / Human-Aligned Phoneme Datasets
| Dataset | Language(s) | Size | Annotation Type | Speech Type | Notes |
|---|---|---|---|---|---|
| GlobalPhone Schultz, 2002 |
22 languages | 400+ hrs, 1,900+ speakers | Native speaker verified | Read speech (news/text) | Covers Arabic, Chinese, German, French, Japanese, Russian, Thai, and more. Phonetic transcriptions via native experts. Commercial license (LDC/ELRA). |
| NIST BABEL IARPA / LDC, 2013–2016 |
25 languages | 40 hrs/language | Human transcribed, forced align | Conversational telephone | Human-annotated word-level transcriptions; phoneme labels derived via language-specific lexicons + forced alignment. Restricted/LDC license. |
| Mboshi Corpus BULB Project, 2017 |
Mboshi (Bantu) | 4.4 hrs, 1 speaker | Linguist transcribed | Elicited / field recordings | 5,130 utterances. Phoneme-level transcriptions by linguists; low-resource language documentation corpus. Freely available on GitHub. |
| DanPASS Grønnum, 2009 |
Danish | 2 hrs | Expert phonetic annotation | Read speech (dialogue-based) | Phonetically annotated spontaneous speech corpus for Danish. Segmented with Praat by trained phoneticians. |
| QuranMB.v2 IQRA Challenge, 2025 |
Arabic | 1,643 utterances | 3 expert linguists | Quranic recitation | Phoneme sequences validated by three Arabic linguistic experts. Used for Arabic pronunciation assessment benchmarking. |
7. Human Phoneme-Labeled Dataset — Urdu
| Dataset | Language | Size | Annotation Type | Speech Type | Notes |
|---|---|---|---|---|---|
| Urdu Phonetically Rich Speech Corpus PRUS / CSaLT · Raza et al., 2009 |
Urdu | 70 min / 708 sentences | Expert linguists for phoneme, force-aligned labeled | Read speech | Greedy sentence selection covering all Urdu phonemic and triphonemic combinations. |
8. Endangered / Low-Resource Force-Aligned Phoneme Datasets (MAUS-Aligner) — DoReCo, 53 Languages
The DoReCo project provides MAUS-aligned, word-level manually verified phoneme annotations for 53 typologically diverse, largely endangered or under-documented languages, most captured as narrative or conversational field recordings.
| # | Language (Glottocode) | Family | Region | Size (approx.) | Speakers | Annotation Type | Speech Type |
|---|---|---|---|---|---|---|---|
| 1 | Anal (anal1239) | Sino-Tibetan | Papua/SE Asia | 2 hrs | 5 | MAUS auto-align, word-lvl manual | Narrative / monologue |
| 2 | Arapaho (arap1274) | Algic | N. America | 1.4 hrs | 10 | MAUS auto-align, word-lvl manual | Narrative |
| 3 | Asimjeeg Datooga (dato1239) | Nilotic | Africa (Tanzania) | 2 hrs | 10 | MAUS auto-align, word-lvl manual | Narrative |
| 4 | Baïnounk Gubëeher (bain1259) | Atlantic-Congo | Africa (Senegal) | 2 hrs | 8 | MAUS auto-align, word-lvl manual | Narrative |
| 5 | Beja (beja1238) | Afro-Asiatic | Africa (Sudan/Eritrea) | 1.8 hrs | 6 | MAUS auto-align, word-lvl manual | Narrative |
| 6 | Bora (bora1263) | Boran | S. America (Peru) | 1.7 hrs | 8 | MAUS auto-align, word-lvl manual | Narrative |
| 7 | Cabécar (cabe1245) | Chibchan | C. America (Costa Rica) | 2 hrs | 5 | MAUS auto-align, word-lvl manual | Narrative |
| 8 | Cashinahua (cash1254) | Panoan | S. America (Peru/Brazil) | 2 hrs | 6 | MAUS auto-align, word-lvl manual | Narrative |
| 9 | Daakie (port1286) | Austronesian | Pacific (Vanuatu) | 0.9 hrs | 5 | MAUS auto-align, word-lvl manual | Narrative |
| 10 | Dalabon (dala1245) | Gunwinyguan | Australia | 2 hrs | 4 | MAUS auto-align, word-lvl manual | Narrative |
| 11 | Dolgan (dolg1241) | Turkic | Eurasia (Siberia) | 2 hrs | 8 | MAUS auto-align, word-lvl manual | Narrative |
| 12 | English (DoReCo) (stan1293) | Indo-European | Eurasia | 2 hrs | 5 | MAUS auto-align, word-lvl manual | Narrative |
| 13 | Evenki (even1259) | Tungusic | Eurasia (Siberia) | 3 hrs | 6 | MAUS auto-align, word-lvl manual | Narrative |
| 14 | Fanbyak (orko1234) | Austronesian | Pacific (Vanuatu) | 2 hrs | 6 | MAUS auto-align, word-lvl manual | Narrative |
| 15 | French (Swiss) (swis1247) | Indo-European | Eurasia (Switzerland) | 2 hrs | 10 | MAUS auto-align, word-lvl manual | Conversation |
| 16 | Goemai (goem1240) | Afro-Asiatic | Africa (Nigeria) | 2 hrs | 5 | MAUS auto-align, word-lvl manual | Narrative |
| 17 | Gorwaa (goro1270) | Afro-Asiatic | Africa (Tanzania) | 1 hr | 8 | MAUS auto-align, word-lvl manual | Narrative |
| 18 | Hoocąk (hoch1243) | Siouan | N. America (Wisconsin) | 2 hrs | 6 | MAUS auto-align, word-lvl manual | Narrative |
| 19 | Jahai (jaha1242) | Austroasiatic | SE Asia (Malaysia) | 2 hrs | 8 | MAUS auto-align, word-lvl manual | Narrative / conversation |
| 20 | Jejuan (jeju1234) | Koreanic | E. Asia (Korea) | 1 hr | 8 | MAUS auto-align, word-lvl manual | Narrative |
| 21 | Kakabe (kaka1277) | Mande | Africa (Guinea) | 2 hrs | 5 | MAUS auto-align, word-lvl manual | Narrative |
| 22 | Kamas (kama1371) | Uralic | Eurasia (Siberia) | 1 hr | 1 (extinct) | MAUS auto-align, word-lvl manual | Elicited (archival) |
| 23 | Komnzo (komn1238) | Yam | Papua New Guinea | 1.2 hrs | 5 | MAUS auto-align, word-lvl manual | Narrative |
| 24 | Light Warlpiri (ligh1234) | Mixed / Pama-Nyungan | Australia | 2 hrs | 8 | MAUS auto-align, word-lvl manual | Conversation |
| 25 | Lower Sorbian (lowe1385) | Indo-European | Eurasia (Germany) | 2 hrs | 8 | MAUS auto-align, word-lvl manual | Narrative |
| 26 | Mojeño Trinitario (trin1278) | Arawakan | S. America (Bolivia) | 1.6 hrs | 5 | MAUS auto-align, word-lvl manual | Narrative |
| 27 | Movima (movi1243) | Language isolate | S. America (Bolivia) | 1.3 hrs | 6 | MAUS auto-align, word-lvl manual | Narrative |
| 28 | Nafsan (S. Efate) (sout2856) | Austronesian | Pacific (Vanuatu) | 2 hrs | 6 | MAUS auto-align, word-lvl manual | Narrative |
| 29 | Nisvai (nisv1234) | Austronesian | Pacific (Vanuatu) | 2 hrs | 5 | MAUS auto-align, word-lvl manual | Narrative |
| 30 | Northern Alta (nort2875) | Austronesian | SE Asia (Philippines) | 2 hrs | 6 | MAUS auto-align, word-lvl manual | Narrative |
| 31 | N. Kurdish (Kurmanji) (nort2641) | Indo-European | Eurasia (Middle East) | 2 hrs | 10 | MAUS auto-align, word-lvl manual | Narrative |
| 32 | Nǁng (nngg1234) | Tuu (Khoisan) | Africa (S. Africa) | 0.85 hrs | 4 | MAUS auto-align, word-lvl manual | Narrative |
| 33 | Pnar (pnar1238) | Austroasiatic | SE Asia (India) | 2 hrs | 6 | MAUS auto-align, word-lvl manual | Narrative |
| 34 | Resígaro (resi1247) | Arawakan | S. America (Peru) | 1 hr | 3 | MAUS auto-align, word-lvl manual | Narrative |
| 35 | Ruuli (ruul1235) | Atlantic-Congo (Bantu) | Africa (Uganda) | 1.2 hrs | 8 | MAUS auto-align, word-lvl manual | Narrative |
| 36 | Sadu (sadu1234) | Sino-Tibetan | E. Asia (China) | 2 hrs | 5 | MAUS auto-align, word-lvl manual | Narrative |
| 37 | Sanzhi Dargwa (sanz1248) | Nakh-Daghestanian | Eurasia (Caucasus) | 2 hrs | 8 | MAUS auto-align, word-lvl manual | Narrative |
| 38 | Savosavo (savo1255) | Language isolate | Solomon Islands | 1.3 hrs | 6 | MAUS auto-align, word-lvl manual | Narrative |
| 39 | Sümi (sumi1235) | Sino-Tibetan | SE Asia (India/Nagaland) | 0.8 hrs | 5 | MAUS auto-align, word-lvl manual | Narrative |
| 40 | Svan (svan1243) | Kartvelian | Eurasia (Georgia) | 2 hrs | 6 | MAUS auto-align, word-lvl manual | Narrative |
| 41 | Tabaq (Karko) (kark1256) | Nubian | Africa (Sudan) | 2 hrs | 5 | MAUS auto-align, word-lvl manual | Narrative |
| 42 | Tabasaran (taba1259) | Nakh-Daghestanian | Eurasia (Caucasus) | 2 hrs | 8 | MAUS auto-align, word-lvl manual | Narrative |
| 43 | Teop (teop1238) | Austronesian | Papua New Guinea | 1 hr | 6 | MAUS auto-align, word-lvl manual | Narrative |
| 44 | Texistepec Popoluca (texi1237) | Zoque | C. America (Mexico) | 1.1 hrs | 1 (archival) | MAUS auto-align, word-lvl manual | Narrative (archival) |
| 45 | Urum (urum1249) | Turkic | Eurasia (Georgia) | 2 hrs | 30 (largest) | MAUS auto-align, word-lvl manual | Narrative |
| 46 | Vera'a (vera1241) | Austronesian | Pacific (Vanuatu) | 2 hrs | 6 | MAUS auto-align, word-lvl manual | Narrative |
| 47 | Warlpiri (warl1254) | Pama-Nyungan | Australia | 2 hrs | 8 | MAUS auto-align, word-lvl manual | Narrative / conversation |
| 48 | Yali (Apahapsili) (apah1238) | Trans-New-Guinea | Papua (Indonesia) | 0.45 hrs | 4 | MAUS auto-align, word-lvl manual | Narrative |
| 49 | Yongning Na (naxi1246) | Sino-Tibetan | E. Asia (China/SW) | 2 hrs | 1 (single) | MAUS auto-align, word-lvl manual | Narrative |
| 50 | Yucatec Maya (yuca1254) | Mayan | C. America (Mexico) | 2 hrs | 8 | MAUS auto-align, word-lvl manual | Narrative |
| 51 | Yurakaré (yura1261) | Language isolate | S. America (Bolivia) | 2 hrs | 5 | MAUS auto-align, word-lvl manual | Narrative |
| 52 | Gurindji (guri1247) | Pama-Nyungan | Australia | 2 hrs | 8 | MAUS auto-align, word-lvl manual | Narrative |
| 53 | Totoli (toto1305) | Austronesian | SE Asia (Indonesia) | 2 hrs | 6 | MAUS auto-align, word-lvl manual | Narrative |
High-resource languages such as English, Japanese, Mandarin, and Arabic benefit from large, professionally or expert-annotated phoneme corpora, while most of the world's languages rely on smaller, forced-aligned, or field-linguist-annotated resources. The DoReCo collection is currently the widest single source of phoneme-labeled data for endangered and under-documented languages, covering 53 languages with MAUS-based forced alignment verified at the word level.